这款“越南版 DeepSeek”,要用 AI 重塑全球软件开发?
这款“越南版 DeepSeek”,要用 AI 重塑全球软件开发?“以前需要3个月开发的网站,现在用Luna,只需3小时。”
来自主题: AI资讯
9314 点击 2025-05-26 10:56
 搜索
搜索
“以前需要3个月开发的网站,现在用Luna,只需3小时。”
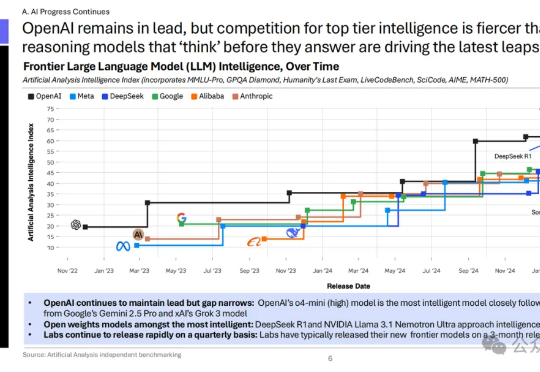
2025年,ChatGPT依旧领跑,但DeepSeek、Qwen等开源劲敌正加速追赶。从「推理革命」爆发到 DeepSeek开源,一场围绕算力、架构与生态的战争已悄然打响,开源势力正以星星之火之势挑战闭源巨头。

在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。

当技术范式重构,强者也不得不重新起跑。
国产大模型进步的速度早已大大超出了人们的预期。年初 DeepSeek-R1 爆火,以超低的成本实现了部分超越 OpenAI o1 的表现,一定程度上让人不再过度「迷信」国外大模型。

随着 Deepseek 等强推理模型的成功,强化学习在大语言模型训练中越来越重要,但在视频生成领域缺少探索。复旦大学等机构将强化学习引入到视频生成领域,经过强化学习优化的视频生成模型,生成效果更加自然流畅,更加合理。并且分别在 VDC(Video Detailed Captioning)[1] 和 VBench [2] 两大国际权威榜单中斩获第一。

就在刚刚,DeepSeek 在全球最大 AI 开源社区 Hugging Face 发布了一个名为 DeepSeek-Prover-V2-671B 的新模型。
新芒xAI今天注意到,备受关注的全球顶级域名 AI.com 跳转目标近日发生变更。目前访问 AI.com 会跳转至一个全新的、充满神秘感的网站。此前该域名曾指向人工智能初创公司 DeepSeek 的相关页面,但根据最新观察,AI.com 现已解绑 DeepSeek。
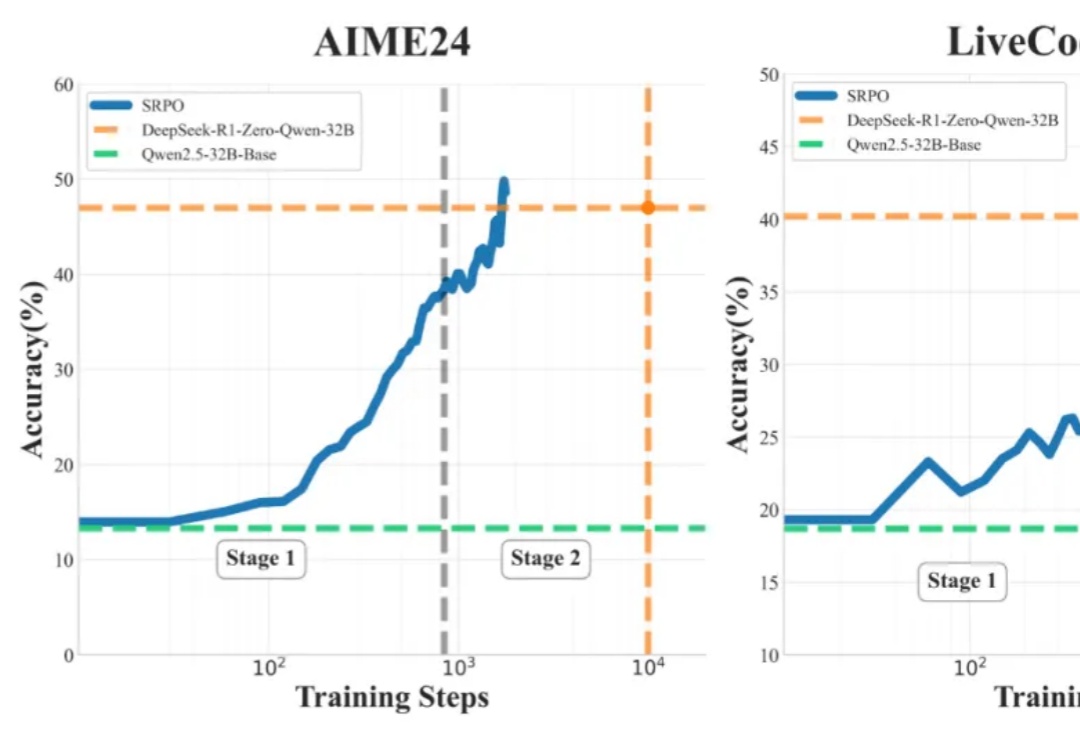
OpenAI 的 o1 系列和 DeepSeek-R1 的成功充分证明,大规模强化学习已成为一种极为有效的方法,能够激发大型语言模型(LLM) 的复杂推理行为并显著提升其能力。

最近,我撞见了一个 DeepSeek 又“认真”又“拧巴”的怪异场景。